外观
01.抽象语法树
抽象语法树是一个非常非常重要,也是一个非常非常常见的知识点,弄清楚抽象语法树有助于我们后面的学习。
上面是抽象语法树呢?当我们遇到一个比较困难的, 感觉难以理解的词的时候,最简单的方式就是拆词,针对抽象语法树我们就可以拆解为三个部分:抽象、语法、树,接下来我们要做的就是针对这三个词注意击破,只要把这三个词搞懂了,那么抽象语法树整体的概念也就能够理解了。
树
树实际上是一种数据结构,我们都知道计算机使用来处理数据,处理数据的第一步就是先要将数据存储进去,那么存储数据的方式就有多种多样。
例如举一个现实生活中的例子,比如我们有一个书柜(计算机)放 10 本书(数据),那么我放置着 10 本书的方式是多种多样的,我可以横着放,也可以竖着放,也可以斜着放。
所谓数据结构,实际上就是数据(书)在计算机(书柜)中组织和管理的一种方式,根据不同的场景,使用合适的数据结构能够帮助我们高效的对数据进行访问和操作。
数据结构如果从大类上面去分类的话,可以分为两大类:线性数据结构 和 非线性数据结构
线性数据结构:数据以线性的方式来进行存储,这种结构又被称之为序列,每个数据在序列中最多只有一个前驱和后驱数据,常见的线性的数据结构如下:
- 数组(Array):一种连续存储空间中的固定大小的数据项集合。数组将相同类型的元素存储在连续的内存位置中,允许通过索引快速访问元素。
- 链表(Linked List):一种由节点组成的线性集合,每个节点包含数据和指向下一个节点的指针。链表允许在不重新分配整个数据结构的情况下插入和删除元素。
- 栈(Stack):一种遵循后进先出(LIFO,Last In First Out)原则的线性数据结构。在栈中,数据项的添加和移除都在同一端进行,称为栈顶。
- 队列(Queue):一种遵循先进先出(FIFO,First In First Out)原则的线性数据结构。在队列中,数据项的添加在一端进行(队尾),移除在另一端进行(队头)。
非线性数据结构:数据之间的存储和关系不是线性的,常见的非线性数据结构:
- 树(Tree):一种分层结构,由节点组成,其中有一个特殊的节点称为根节点,其余节点按照层级组织。每个节点(除根节点外)都有一个父节点,可以有多个子节点。常见的树结构有二叉树、红黑树、AVL 树等。
- 图(Graph):一种由顶点(节点)和边组成的数据结构,边连接了顶点。图可以是有向的(边有方向)或无向的(边无方向)。图可用于表示具有复杂关系的数据集合。
没有什么最优秀的数据结构,只有根据你的处理场景最合适的数据结构。
例如数组,它在内存中是一段连续的地址:
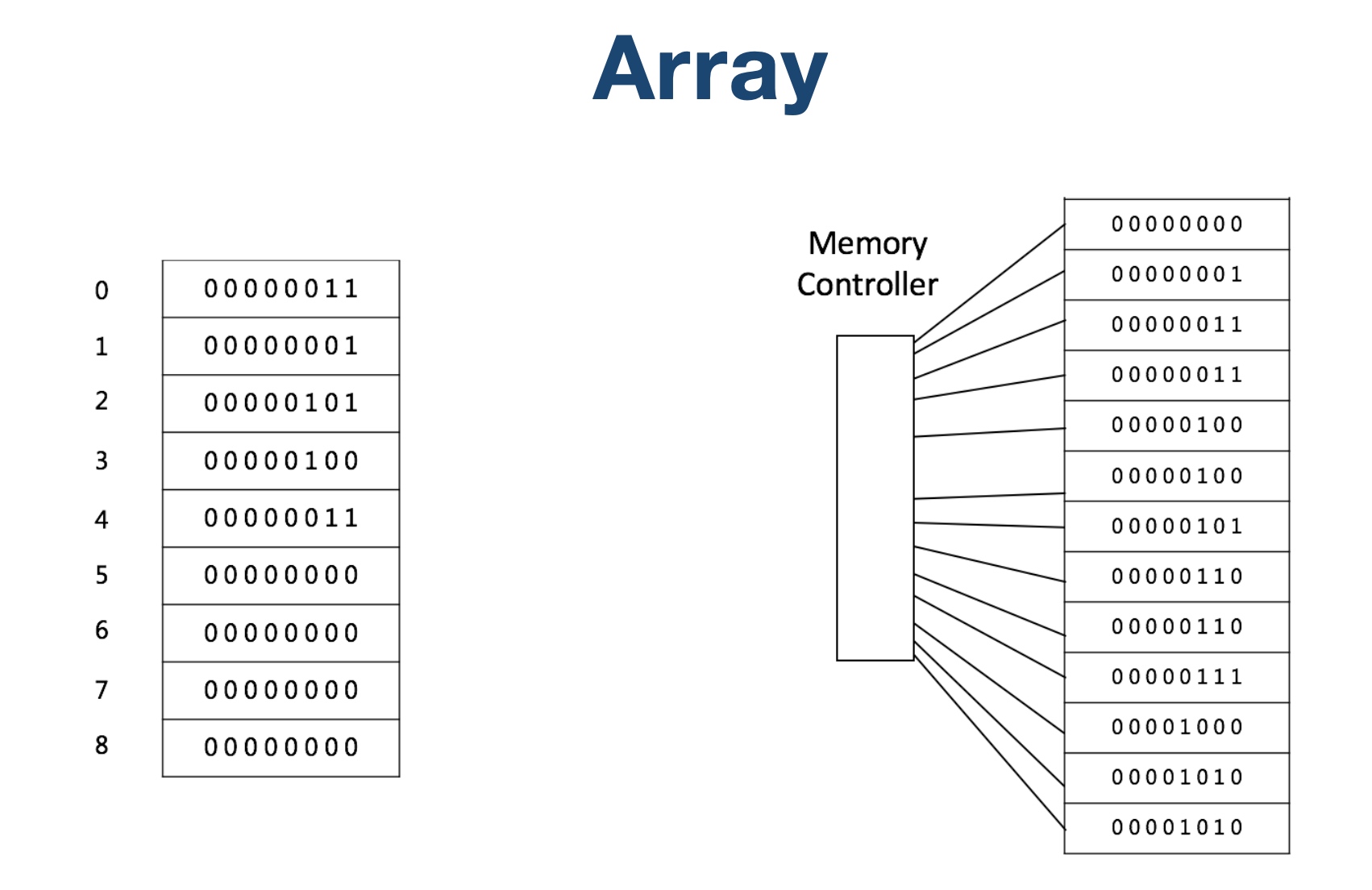
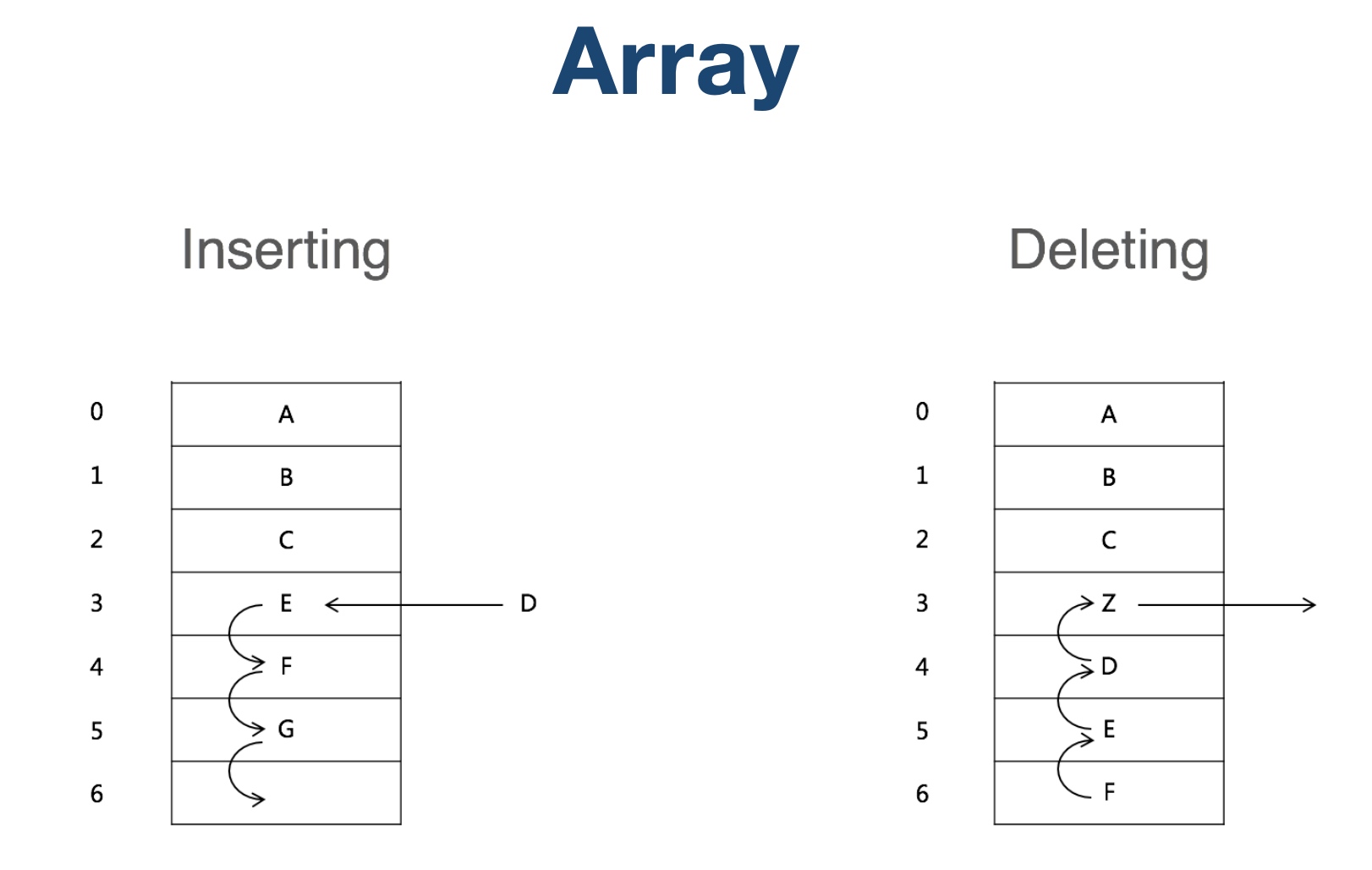
这种数据结构的特点就决定了当我们要查找一个数据的时候就会非常的方便,速度很快,因为只需要指定下表,然后通过内存地址的偏移量就能够查找到该数据。但是当我们要插入或者删除一个数据的时候,要做的工作就比较多了,例如当插入一个数据当中间的时候,需要将插入位置后面的所有元素全部进行后移。
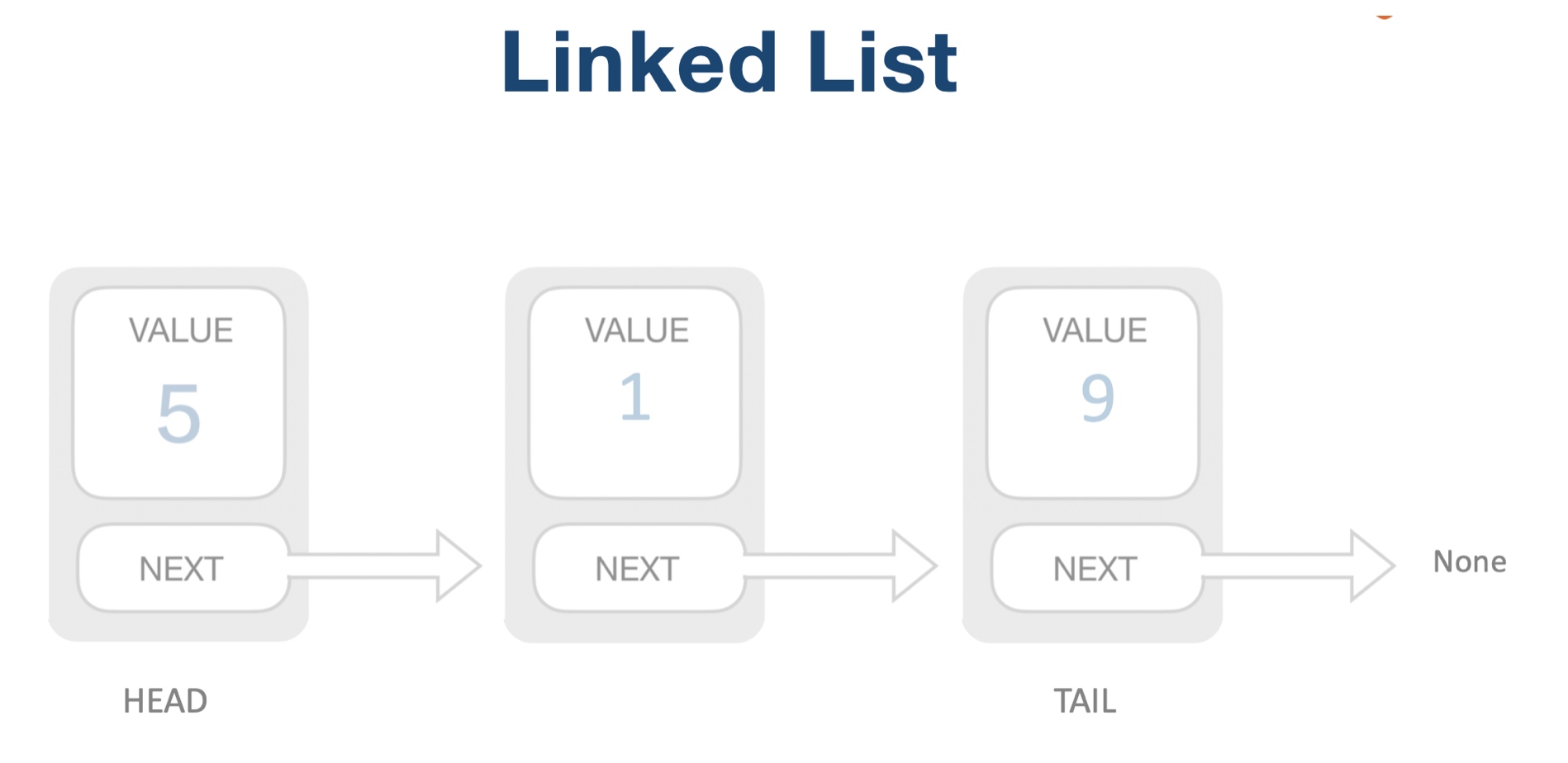
再比如说另外一种线性数据结构链表,它的特点就是在内存中并非连续的存储,而是通过一个 next 字段指向下一个数据的内存地址。
这种数据结构的特点,就决定了链表在插入和删除元素的时候,相比数组会更加高效,例如下面是插入元素的图解:
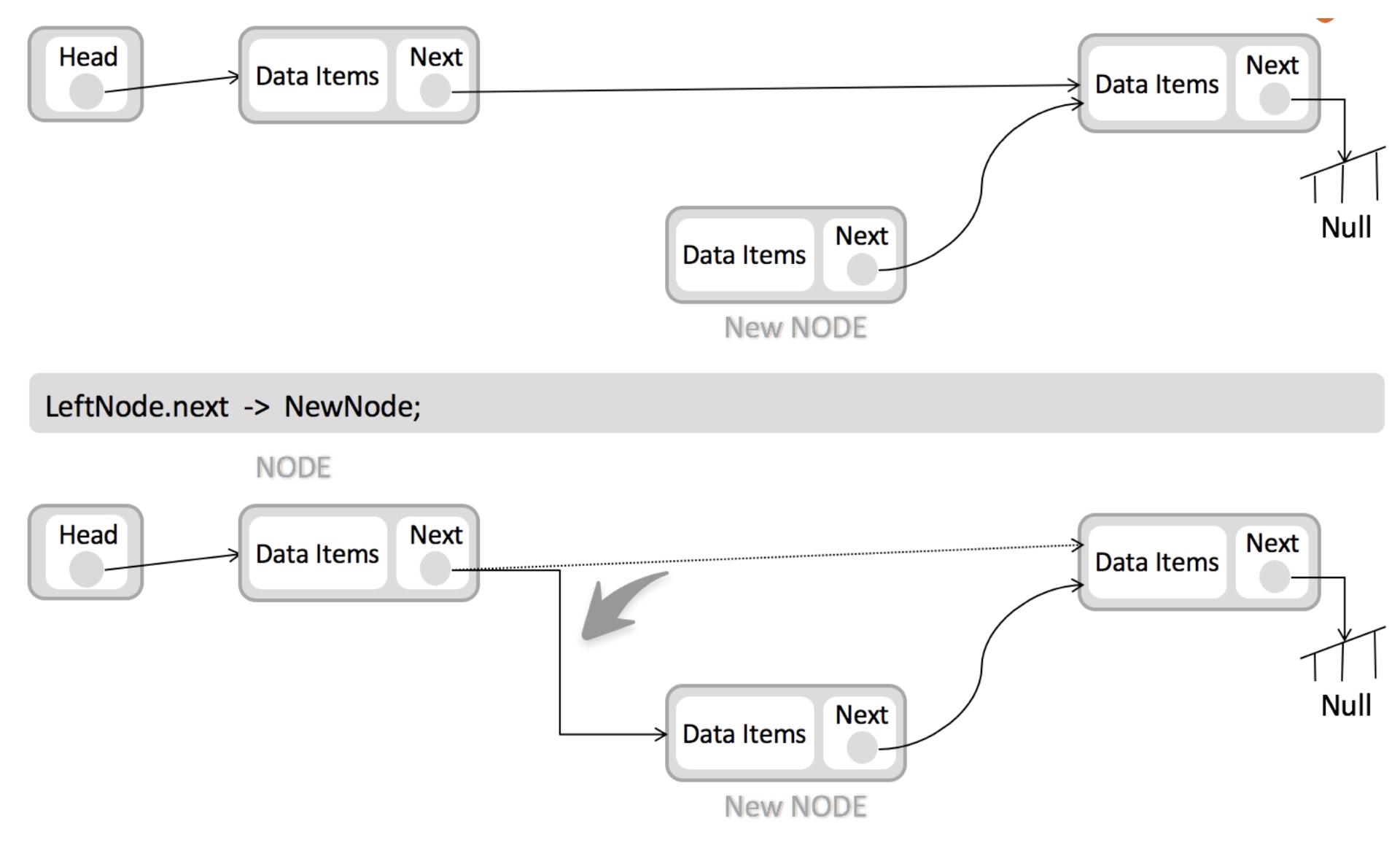
下面是链表删除元素的图解:
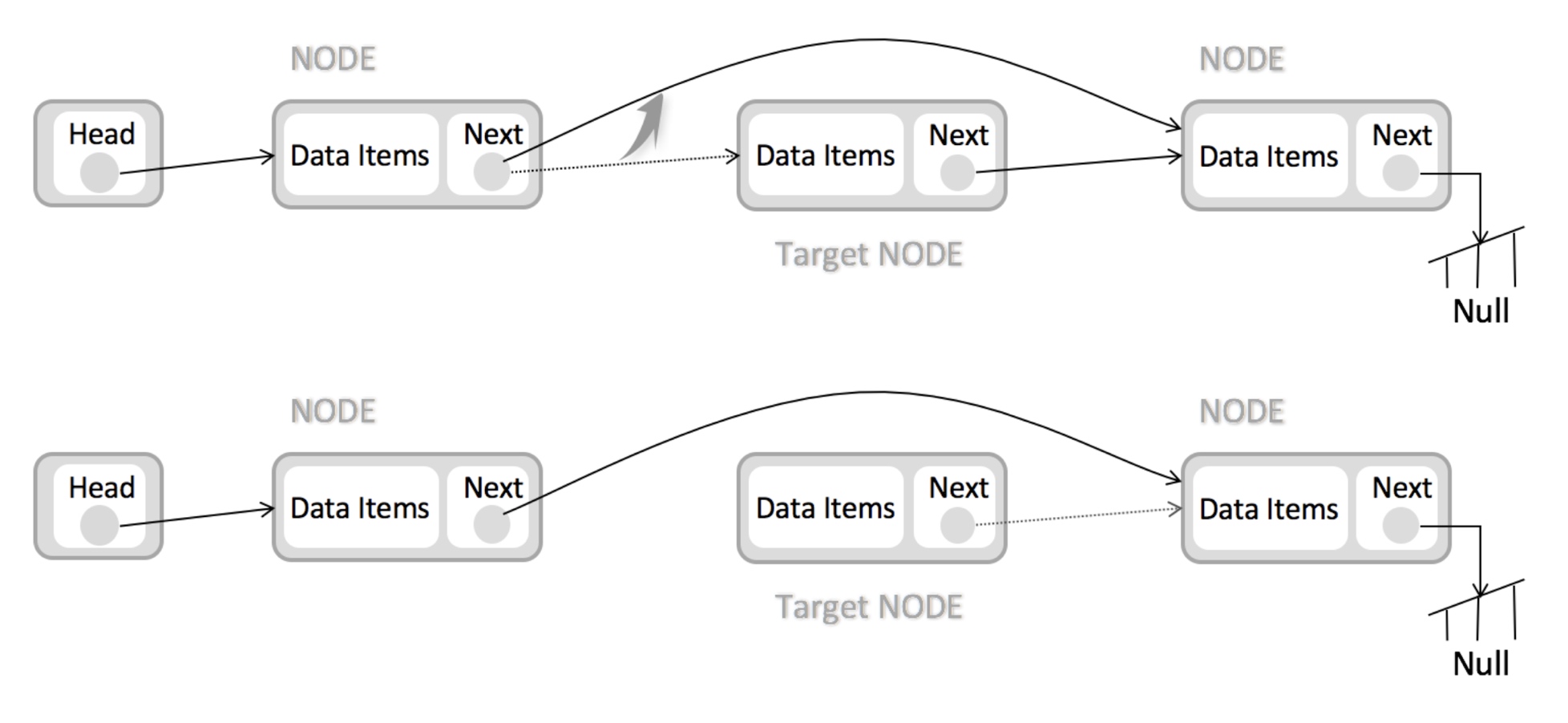
但是链表要去查找元素的效率就比数组要低,需要一个一个的去查询。
因此通过上面的例子,我们可以知道一件事情:没有一种数据结构是完美的,假设有那么一种完美的数据结构,那么其他数据结构就没有存在的意义了。
接下来让我们回到“树”这种数据结构,树这种非线性的数据结构在解决某些问题的时候,具有如下的优点:
层次关系:树结构可以非常自然地表示数据之间的层次关系,如文件系统中的目录结构、组织结构、语法分析树等。通过树结构,可以清晰地展示数据的从属关系和分层结构。
搜索效率:对于某些类型的树(如二叉搜索树、AVL 树、红黑树等),在保持某种顺序或平衡条件的情况下,搜索效率比线性数据结构(如链表、数组)要高得多。在平衡二叉搜索树中,搜索、插入和删除操作的时间复杂度通常为 O(log n),其中 n 为树中节点的数量。
动态数据集合:与数组等固定大小的数据结构相比,树结构可以方便地添加、删除和重新组织节点。这使得树结构非常适合用于动态变化的数据集合。
有序存储:在二叉搜索树等有序树结构中,数据按照一定的顺序进行组织。这允许我们在 O(log n) 时间内完成有序数据集合的操作,如查找最大值、最小值和前驱、后继等。
空间优化:在某些应用场景中,树结构可以有效地节省空间。例如,字典树(Trie)可以用于存储大量字符串,同时节省空间,因为公共前缀只存储一次。
分治策略:树结构天然地适应分治策略,可以将复杂问题分解为较小的子问题并递归求解。许多高效的算法都基于树结构,如排序算法(归并排序、快速排序)、图算法(最小生成树、最短路径等)。
上面的这些优点,如果你没有系统的学习过数据结构相关的知识,是比较难理解的,但是并不影响我们后面的学习。
目前,你只需要知道“树”是一种数据结构,并“树”这种数据结构有很多的优点即可。正因为“树”这种数据结构有上述的那么些优点,所以你在很多地方都能看到它的身影:DOM 树、CSSOM 树、Vue 模板树、语法树。
语法树
什么是语法树呢?简单来讲,就是将我们所写的代码转为树的结构。
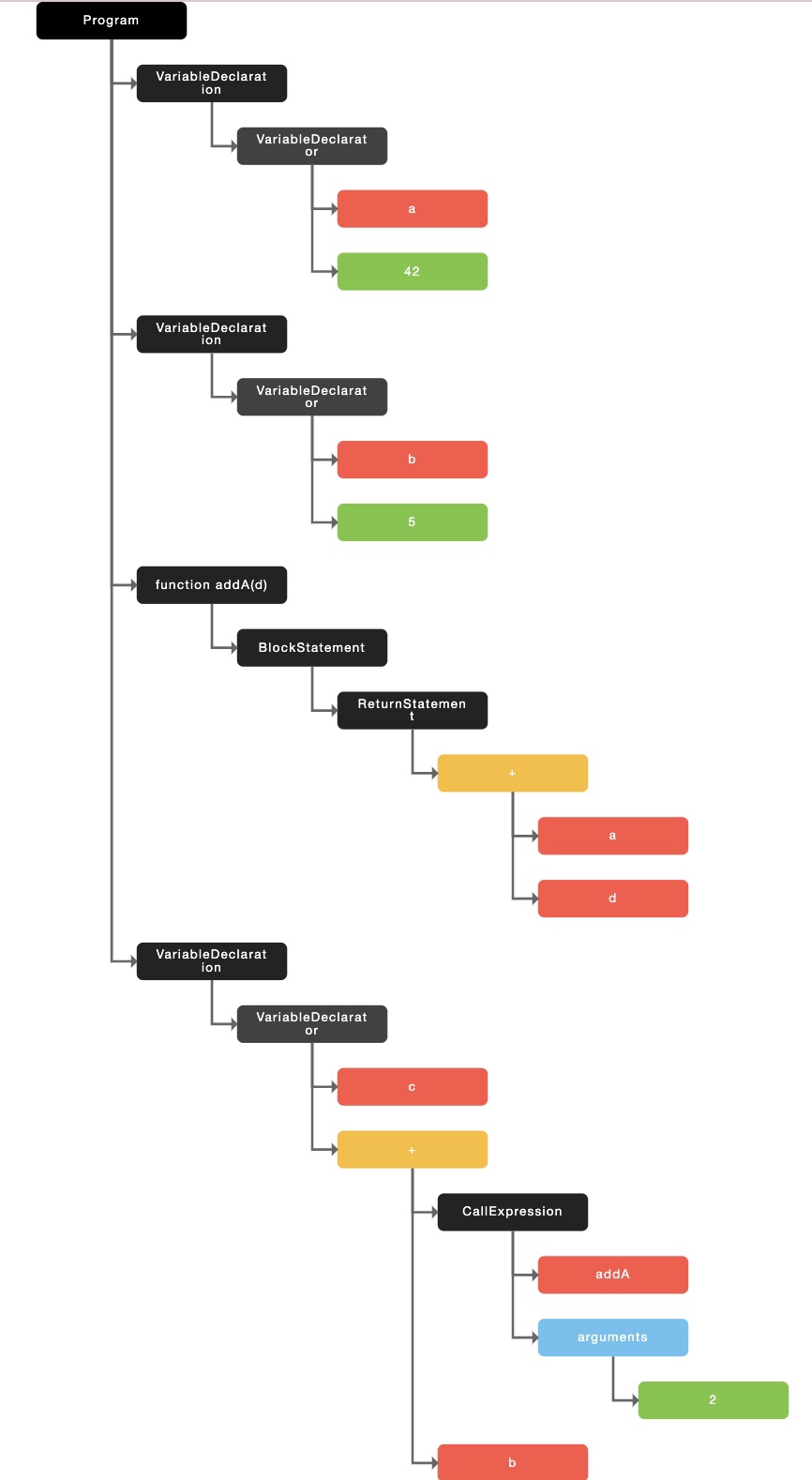
假设有如下的代码:
var a = 42;
var b = 5;
function addA(d) {
return a + d;
}
var c = addA(2) + b;对于上面的这段代码,编译器或者解释器是看不懂的,对于它们来讲,就是一段连续的字符串:
'var a = 42;var b = 5;function addA(d) {return a + d;}var c = addA(2) + b;';编译器或者解释器会对上面的代码进行整体的扫描分析,分析出来上面的字符串中哪些是关键字、哪些是标志符,哪些是运算符,形成一个一个的 token(最小的不可再拆分的单位)
例如上面的那一段代码,分析出来的结果如下:
Keyword(var) Identifier(a) Punctuator(=) Numeric(42) Punctuator(;) Keyword(var)
Identifier(b) Punctuator(=) Numeric(5) Punctuator(;) Keyword(function)
Identifier(addA) Punctuator(() Identifier(d) Punctuator()) Punctuator({)
Keyword(return) Identifier(a) Punctuator(+) Identifier(d) Punctuator(;)
Punctuator(}) Keyword(var) Identifier(c) Punctuator(=) Identifier(addA)
Punctuator(() Numeric(2) Punctuator()) Punctuator(+) Identifier(b) Punctuator(;)最终,会采用“树”这种数据结构来存储上面的 token 数据,最终形成一颗语法树
有一个在线的网站,大家可以将自己的源码放上去,能够看到对应源码所生成的语法树:https://www.jointjs.com/demos/abstract-syntax-tree
抽象
最后解释一下“抽象”。
需要注意一下,在计算机科学里面的“抽象”这个词和现实生活中“抽象”这个词的含义是不太相同的,现实生活中“抽象”的含义是指“很模糊”的意思。
在计算机科学里面,抽象是一种思维方式,具体指的是从一个具体事物中提取出 本质特征、概念和规律,忽略 不相关的细节。这个实际上是一种非常非常重要的方式,通过这种方式,我们可以将某个复杂的问题分解成更简单的,更纯粹的小问题,从而帮助我们更容易的解决复杂问题。
明白了抽象的概念之后,我们再来看抽象语法树,在将源代码转换为树结构的时候,只会关注代码的结构和语法,会忽略具体的字符、空格、换行这些表达细节,像这些不重要的表达细节,在形成树结构的时候通通会被丢弃掉。
抽象语法树
抽象语法树(Abstract Syntax Tree,简称 AST)是编程语言中一种树形的数据结构,用于表示源代码的语法结构。
在 AST 中,每个节点代表源代码中的一个语法元素(如变量、表达式、语句等),并且描述了这些元素之间的层次关系。在从源代码转为语法树的过程中,会采用到抽象的思想,只关注代码的结构和语法,忽略具体的字符、空格、换行等表达细节。通过这种抽象表示,我们可以更方便地理解、分析和操作源代码,而无需直接处理文本格式的代码。
抽象语法树在编译器和解释器设计、代码分析、代码转换等领域具有广泛的应用。使用 AST 可以简化代码处理过程,提高代码操作的精确性和可扩展性,并有助于实现高效的代码优化和转换算法。